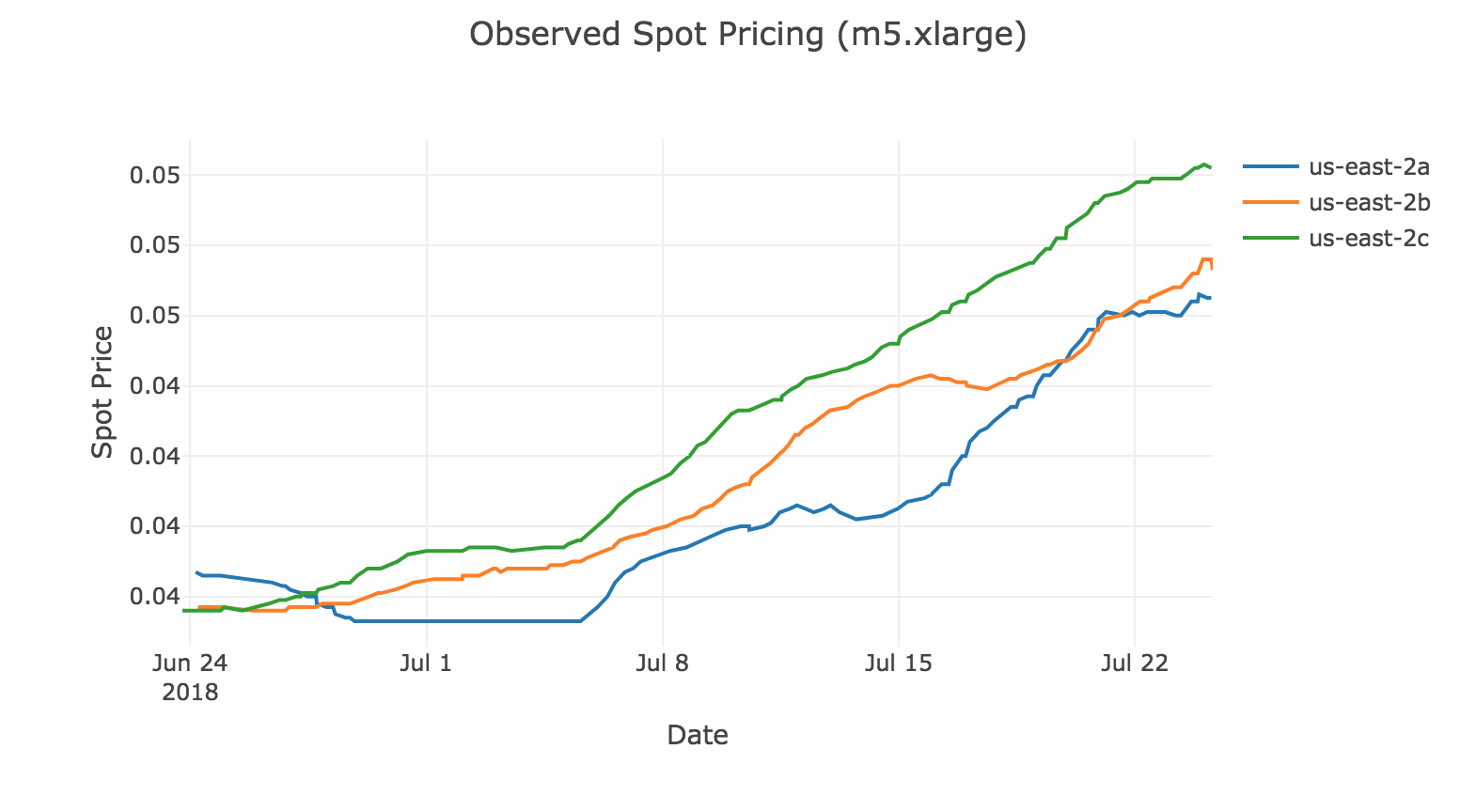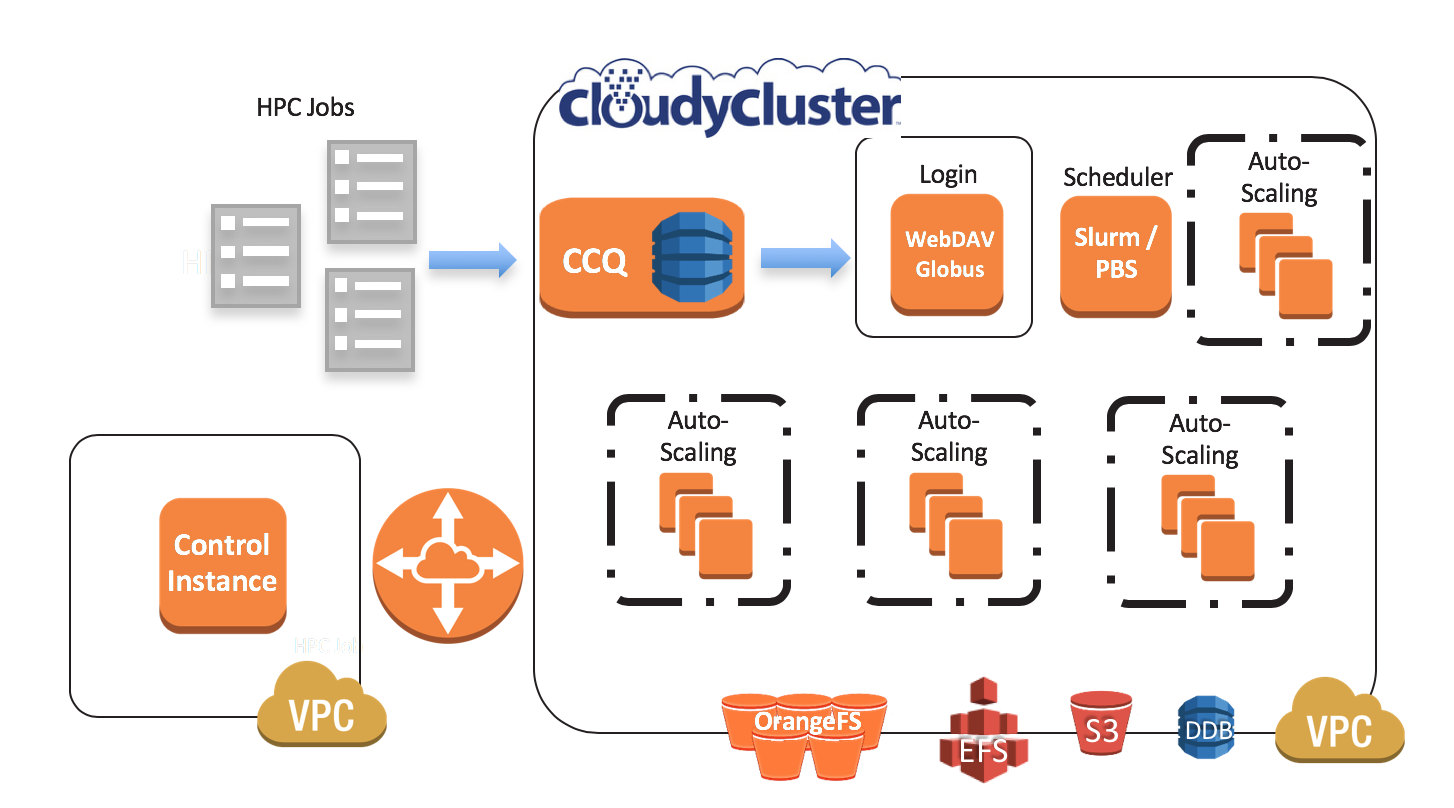
 Yates Laboratory at The Scripps Research Institute is Pushing for Better Understanding of Cystic Fibrosis with the help of Cloud HPC on AWS with CloudyCluster and IP2
Yates Laboratory at The Scripps Research Institute is Pushing for Better Understanding of Cystic Fibrosis with the help of Cloud HPC on AWS with CloudyCluster and IP2
Cystic Fibrosis (CF) is one of the most common inherited childhood diseases, impacting 1:4,000 children born in the US (www.cff.org). CF is caused by mutations in the gene that encodes the Cystic Fibrosis Transmembrane Conductance Regulator …
Read More