
Scaling HPC in AWS
On Jul 12, 2018
We have been approached by many people wanting to scale their science or engineering to the scale of the 1.1m vCPU run recently completed by the DICE Lab at Clemson. In addition, others have wanted to automate their workflows in AWS as well. We have created this paper to demonstrate how to use the pattern created by this project for your own workflows. This paper will hopefully help guide people through the process and the tools used.
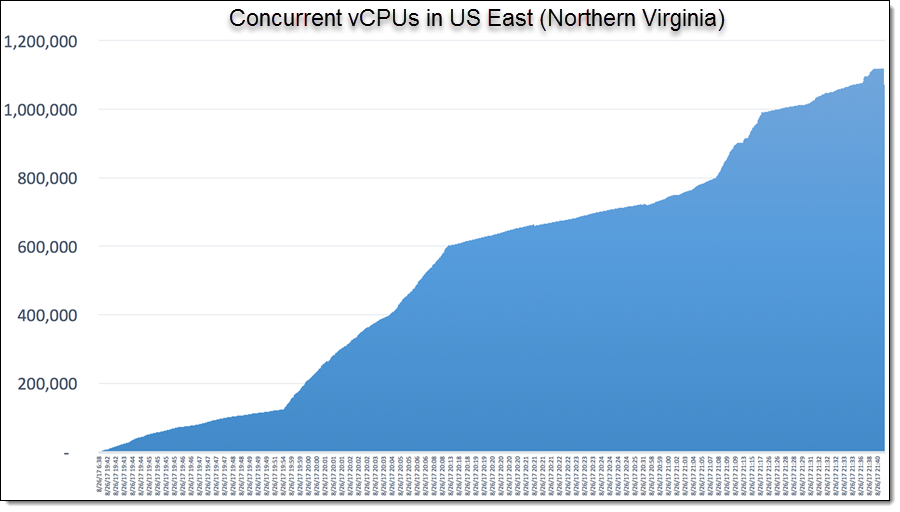
Scale Achieved
49,925 EC2 Spot Fleet Instances
1,950 TB of EBS Storage
1,119,196 vCPUs at Peak
The breakdown of the EC2 instance types that they used:
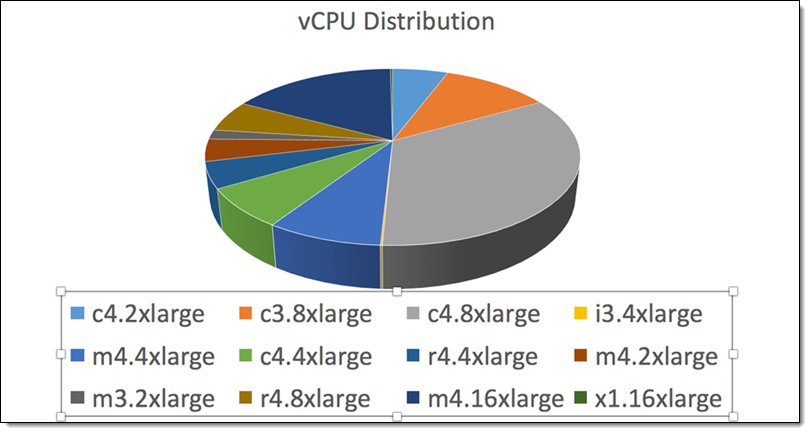
Science
As background, the impetus of the Clemson cloud HPC run, there were discussions on how to scale topic modeling through Natural Language Processing, due to limitation, many experiments in this space are ignored. With the scale of AWS, researchers were able to try many parameters in this process that were otherwise unthinkable.
Topic modeling is a common text analysis technique in machine learning. In the experiment they ran Parallel Latent Dirichlet Allocation (PLDA) and vary numerous experimental parameters (e.g., the number of topics) to better understand how they affect the output models. They also ran each experimental parameter combination many times in order to capture its tolerance to random seeds.
The Clemson team conducted their scalability experiments on two datasets: the full text NIPS conference proceedings, and a set of abstracts from computer science publications provided to them through support from HPCC Systems, LexisNexis Risk Solutions RELX Group, and Elsevier Scopus
The scalability of the experiment produced a relative large quantity of results for NLP analysis on how the various parameters for PLDA affected the sensitivity of the output.
Tools
CloudyCluster: an automated system for providing HPC infrastructure in the cloud using standard tools and processes used by hundreds of thousands of users worldwide. It takes the concepts used for years in on premise HPC and brings it elastically to the cloud. CloudyCluster is available in the AWS Marketplace.
CCQ:
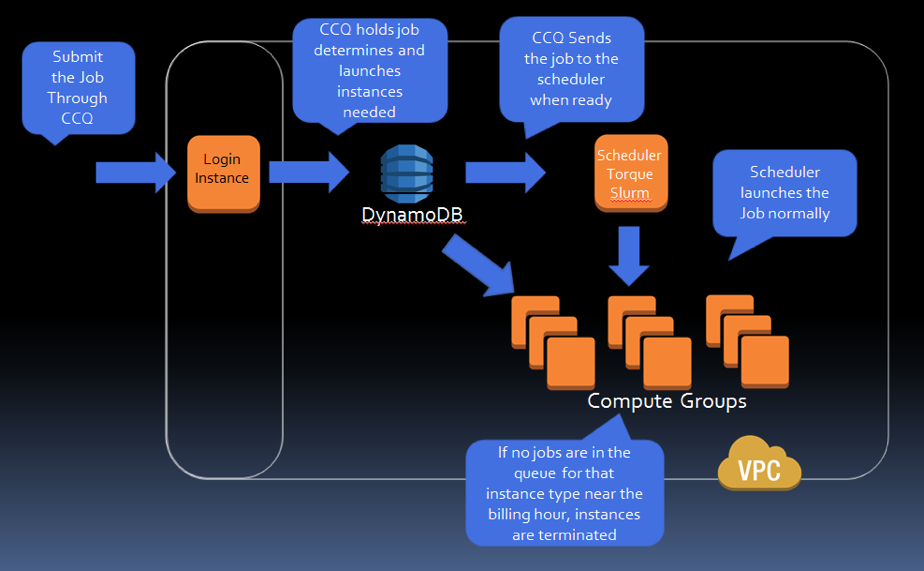
CCQ Meta-scheduler
PAW / Automaton:
PAW a.k.a. The Automaton project is an open source project that allows you to build custom templates to automate HPC workflows. The templates are used to create HPC environments with CloudyCluster, launch jobs and when complete can tear down the HPC environments. It was designed to optimize costs while allowing for workflow automation.
Builderdash:*
An open source project to automate the building of cloud disk images. It leverages a configuration file that allows users to state what software needs to be installed, compiled and configured on top of an existing cloud disk image. This is used as a base to build CloudyCluster but also can be used to add additional required software to an image. To achieve large scale, images have to be predefined. If you are running at scale you don’t want to pay for configuration management to do many minutes of work on an instance before it can be used. Builderdash combined with CloudyCluster enable scaling.
Security
Security is a key aspect of R&D which leverages HPC heavily. Researchers and Engineers have to rely on security of the data being processed, from privacy concerns over healthcare data to critically proprietary data for companies.
With this in mind Omnibond developed CloudyCluster to be a secure system that automates and simplifies the process of running HPC at scale in a customers own AWS account. Building on the security and privacy investment of AWS, CloudyCluster can be configured for extremely security conscious environments including secure HPC parallel storage based on OrangeFS and encrypted EBS volumes, Multi Factor Authentication. The AWS Marketplace reviews verify that only the customer has access to the data in the environment.
When CloudyCluster is in operation it follows the AWS best practices for security, including placing all storage and compute in a secure VPC and only enables limited access through bastion hosts which run regular security updates. If there are site specific security requirements, a customer can take the base CloudyCluster ami and add its own software independently.
Phase 1: Create the Base Environments with PAW/Automaton
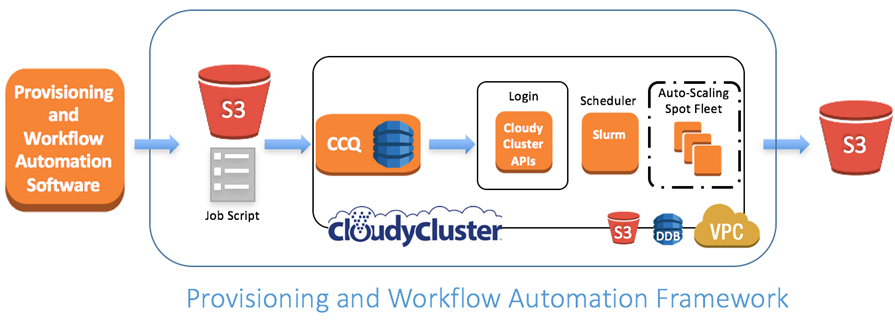
Brief overview of How PAW/Automaton works with CloudyCluster
A core component of PAW is CloudyCluster, which supports the dynamic provisioning and de-provisioning of HPC environments within AWS. The provisioned environment can include shared file-systems, NAT instance, compute nodes, parallel file-system, login nodes, and schedulers.
PAW accesses most AWS services through CloudyCluster APIs, and utilizes these APIs to perform many automation tasks. CloudyCluster provides several configuration options, such as the choice of scheduler and shared home directories. All environment customization within PAW is accomplished through templates. PAW comes prepackaged with a CloudyCluster template generator and several standard CloudyCluster environment templates. The template generator allows users to create, share, and modify their own CloudyCluster environment templates.
After the user chooses a template, CloudyCluster executes the required AWS API calls to dynamically provision and configure the requested environment resources. CloudyCluster also pre-configures the selected scheduler (e.g., Torque or Slurm), creates users on the nodes, and mounts the requested file-systems on every node.
CloudyCluster provides a meta-scheduler called Cloudy Cluster Queue (CCQ) that provides job-driven autoscaling via either special directives within the job script or through parsing certain information from supported HPC job directives.
Config
The automation is driven by a ini style configuration file that defines the parameters required to execute. The configuration file has six different sections:
UserInfo
Contains the information about the users that will run the jobs/workflows specified in the configuration file. The specified users are created within CloudyCluster and provisioned to the created environment.
General
Contains parameters about the configuration such as the cloud type and the environment name.
Cloud Type Settings
This section is named dynamically and the name is based on the environment and cloud type being used. It contains the information relevant to the desired environment and cloud types. For example, currently the only EnvironmentType implemented is CloudyCluster and the only CloudType implemented is AWS, so the section header is titled CloudyClusterAws. This contains the information required to set up CloudyCluster on AWS, such as the region, keypair, VPC, and subnet. Much of this information is already pre-defined for the user. However, there are some parameters, such as the VPC ID and Subnet ID, that are unique to each user and do not have default values.
Environment Settings
This section is also dynamically named and contains parameters that pertain specifically to the type of environment being created. The sample configuration file section header shows CloudyClusterEnvironment. The environment key pair, region, and cluster configuration required by CloudyCluster are defined in this section.
Computation
This optional section of the configuration file allows users to define job scripts or user-defined workflows that they want to execute on the newly created environment. These user-defined workflows, such as the topic modeling workflow used for the example experiments, can be created by the user and integrated directly, which minimizes the configuration required. When extended to multiple environments, this allows users to define a single workflow that can be submitted to multiple newly created environments easily. Any job script, local or remote, that the user wants to run on a cluster environment can also be defined in this section. The specified scripts (local or remote) is sent to the environment if needed and executes it using the scheduler defined by the environment.
Environment Templates
This optional section is also dynamically named. It is utilized by the CloudyCluster Environment template generator to generate CloudyCluster Environment templates that can then be referenced in the Environment Settings section to reduce the length of future configuration files. The parameters in this section define the CloudyCluster environment configuration that will be put into the template. There are a number of pre-generated templates that researchers can use and extend as customized environment templates. The template generator supports the full range of customization options provided by CloudyCluster which allows researchers to fine tune their environments to better suit the requirements of their workflows.
Phase 2: Use PAW/Automaton to launch CCQ spot fleet jobs
Spot Fleets
A Spot Fleet is a collection, or fleet, of Spot Instances. The Spot Fleet attempts to launch the number of Spot Instances that are required to meet the target capacity specified in the Spot Fleet request. The Spot Fleet also attempts to maintain its target capacity fleet if your Spot Instances are interrupted due to a change in Spot prices or available capacity.
The Clemson team identified AWS Spot Fleets as the most suitable tool for creating the compute nodes for the environment. They also considered the AWS Autoscaling service with Spot Instances. However, a Spot Autoscaling group can only use one AWS instance type per group, whereas AWS Spot Fleet can utilize multiple AWS instance types within a single fleet, depending on the Spot Bid Price and “weight” specified. If the price of the requested instance type in a Spot Autoscaling group spikes before all instances are allocated, the group may not reach its target capacity. Spot Fleets are protected from such a price spike for a given instance type by allowing use of other instance types in case the price of one instance type spikes.
Custom workflow and how it works
Workflow templates are powerful and allow for easy customization of the system to specific domains and tasks. A workflow template is defined as a custom set of tasks or actions that are defined by the user that can then be submitted to an HPC scheduler to perform work. These workflow templates allow users to create and share their own workflows with other users by simply sharing their custom Workflow classes.
A custom Workflow class must implement the run and monitor methods. Code to generate or read a batch script file is added to the run method and any special monitoring code required for monitoring the completion of the workflow is put in the monitor function. For example, the monitor could include monitoring a specific path for an output file or monitoring the number of jobs. Users can also implement a custom workflow that utilizes another workflow manager such as SWIFT or QDO to execute the workflow. In these types of workflows PAW can be utilized to dynamically create the resources required by the workflow management tool.
The Clemson team implemented a Topic Modeling Pipeline Workflow class that reads in a configuration file, obtains the experiment parameters, performs a number of pre-processing tasks, and then submitts a very large number of MPI jobs to the environment automatically. Since this workflow is integrated into PAW, it can be run by adding an extra line to the Computation section of the configuration file.
CCQ Overview
The integration with CCQ and the job level autoscaling provided by CCQ are key features that make PAW/Automaton different from the other utilities that provision cluster environments. Utilizing CCQ, PAW can submit a job that dynamically creates the exact resources that the workflow job requires, and release the job to the HPC scheduler only when the resources have been successfully created. All of the job submission and communication performed with CCQ is accomplished through the web based APIs.
The process is able to use AWS Spot pricing since both CloudyCluster and CCQ are able to utilize the AWS Spot market. The Spot market allows users to bid for unused capacity on AWS. Use of Spot can decrease costs, as the average spot prices for different instances types is up to 90% less than the on-demand price for the same instance type. Workflows accesses the Spot market via simple directives that are added to existing job scripts. This feature is also exposed with CCQ and CloudyCluster through its configuration file.
Job Script Generation
PAW/Automaton generates the job script through a custom workflow class that was implemented to allowing submission of the entire workflow with a single command. The custom workflow implements the run and monitor methods that perform the required operations. The custom workflow then generates a specific CCQ job script that is then submitted to the CCQ scheduler.
Results Sent To S3
The workflow had each job, on completion, send its output to designated directories in S3. This enabled scalability where all nodes could output to a relative bucket increasing the capability of high throughput output. This also assured that the data was protected by the high availability of S3.
Job Time Threshold
To submit workflows for a certain duration, directives can be added to the CCQ jobs to stop processing after a certain amount of time. This enables cost management through the limitation of how long a workflow can run.
Conclusion
The combination of CloudyCluster, Paw/Automaton, Builderdash and AWS provide a powerful set of tools to accomplish automated HPC workflows at scale. Providing the heavy lifting, these tools make it easier for workflows to be moved to the cloud and tightly integrated without worry of queues or limited allocations.