
AUTOMATING CLOUD HPC RESOURCE MANAGEMENT WITH CLOUDYCLUSTER
On May 4, 2016
At ISC I was intrigued to learn about the CloudLightning project because it has goals to make cloud operation more efficient from an operational perspective, down to a reduction of the electrons consumed in delivering services. The specific aspects of self-organisation and self-management truly resonate with me as some of the foundational ways the cloud needs to evolve. CloudyCluster incorporates aspects of these self-organisation and self-management goals. The purpose of this blog post is to give an overview of the CloudyCluster approach, and how we designed it to utilise and automate cloud resources for HPC consumption. I will dig into some aspects that may relate to CloudLightning goals.
THE GOALS FOR CLOUDYCLUSTER:
- Make sustainable HPC accessible to a broader community. The cloud is a key component.
- Build HPC systems in the cloud that benefit from the advance features of the cloud but feel like traditional HPC systems to the users, so it’s easy for new users to adopt the cloud for HPC. For example, users need a choice of schedulers, a choice of storage optimized for the workload and choice of instance capabilities (memory, cpu, gpu, etc.) on a job granularity level.
- Self Service: we wanted engineers, scientists, researchers and others who rely on parallel and HPC computing to be able to create and tear down clusters in their own Cloud accounts as often as they want. We did not want them to have to talk to someone, but we are available if they want to talk to someone.
- We wanted to include a wide variety of common open software and libraries pre-configured, so time to computing is as short as possible. In addition to the open software provided, we wanted it to be easy to add software that might require licenses or that is custom created.
- Cloud Capabilities: in addition to the familiar HPC capabilities, the API-driven cloud opens up new opportunities to enhance the computing experience. We wanted to take advantage of the massive scale of the cloud and the ability to dynamically scale resources up and down to fit job workloads. We want to provide all of this while still fitting into the paradigm of how HPC systems are expected to work and making the transition to the cloud as seamless as possible.
- Costs for CloudyCluster should be cloudlike as well: cost-efficient and pay as you go. This includes supporting cloud features such as spot instances and reducing extra costs for the computational researcher.
THE IMPLEMENTATION:
The entry point for the CloudyCluster user is a self-service, responsive, designed user interface using xhr requests to web services provided by the control instance, which is launched from the AWS marketplace. This interface is designed to take the various infrastructure services available from the cloud provider that are required to create an HPC environment and present the appropriate options, so they can be combined to meet user needs.]
CCQ Meta-scheduler
After the control instance is launched from the AWS marketplace, the orchestration of the various AWS services is simplified to a 3-screen process to get to a running, completely configured elastic HPC cluster.
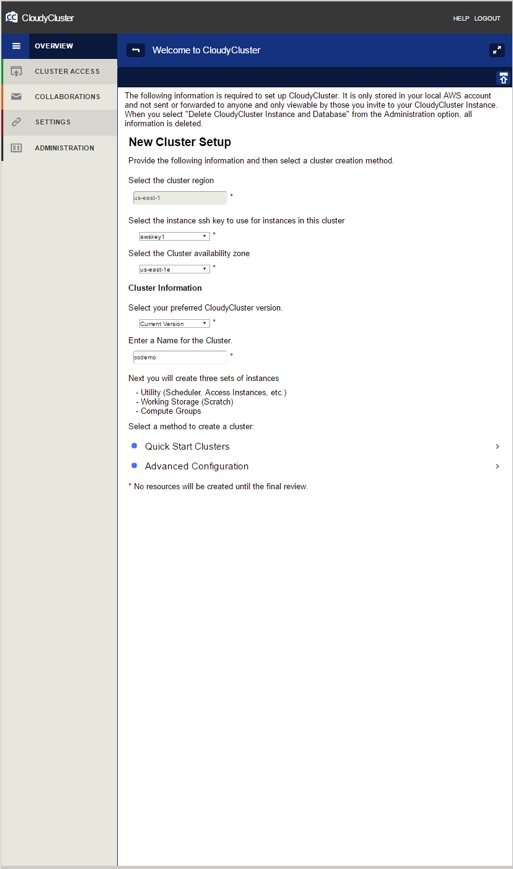
v1.1 New Environment Setup
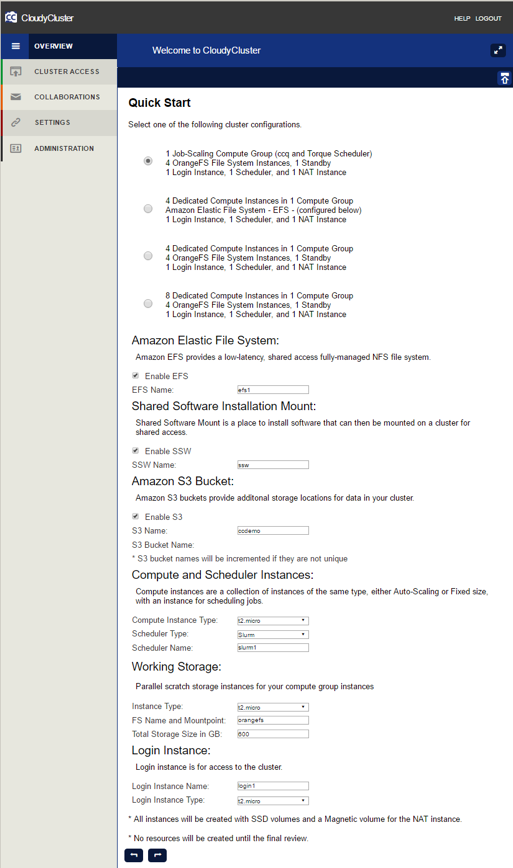
v1.1 Quick Start Options

v1.1 Pricing Review

v1.1 Overview Page
BEHIND THE SCENES:
The process starts with what we affectionately call the franken-AMI. This single ami, when launched, can become any one of many core HPC cluster components: scheduler, compute, login or parallel storage instance. These instances incorporate some of the concepts of self-organisation and management. They are launched by the control instance and are directed by what they are going to be, but as they come up they assume the role that makes the most sense.
For example, with the parallel file system OrangeFS, in an n+1 configuration, each FS instance comes up as part of an auto-scaling group. The first ones to come up become active FS instances, and the final one that comes up will assume the role of standby instance. In the event of failure of an active FS instance, the standby instance will assume the EBS volumes of the failed instance and then take over the role. The auto-scaling group will create a new instance, and it will then assume the standby role.
The scheduler instance is launched and self configures for the scheduler selected in the UI. The scheduler can be configured with a persistent compute group or job-based auto-scaling with CCQ.
Login instance(s) are created and are used for job submission and data transfer with scp, webDAV, or through a dynamically configured Globus end-point. VisualHPCtm can be enable for the login instance(s) on a per user basis, enabling persistent VNC connections.
All of the heavy lifting of connecting and provisioning is handled by CloudyCluster, including user and group provisioning to all the instances, mounting of the selected file systems, creation, pausing and terminating. This leaves more time for using and requires less for administration.
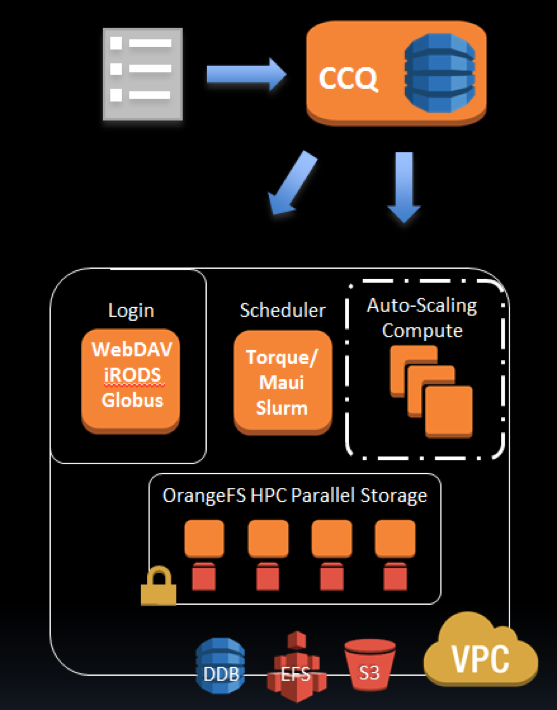
Architecture
ELASTIC COMPUTATION:
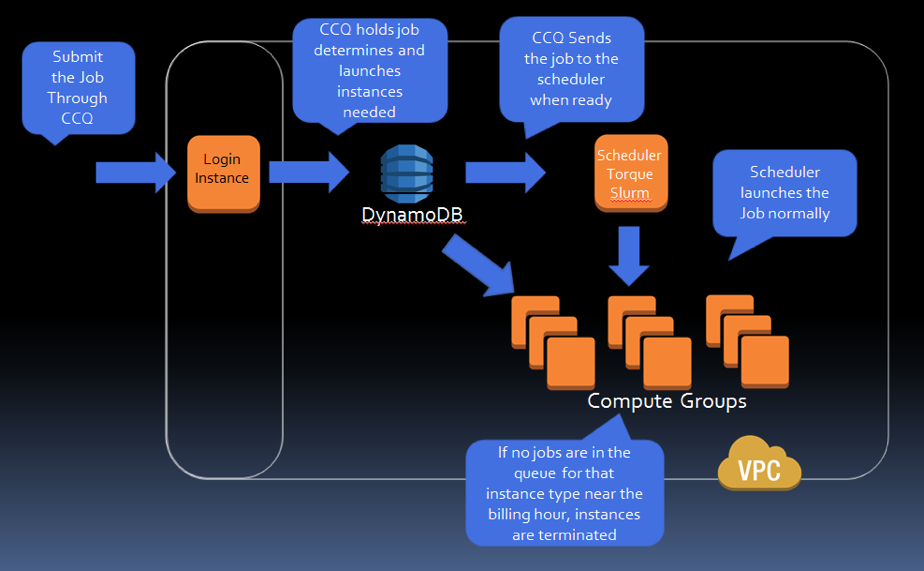
With a resource approaching infinity relative to a static cluster, the concept of jobs no longer represents a scheduling problem; it’s more akin to a dispatching problem. CCQ serves to spin up the number of instances required to complete the job, but users can set upper limits if desired. Thus, CCQ is bridging the gap to familiar computing environments, providing a front end for common schedulers enabling elastic computation.
To accomplish this CCQ provides a command line interface that is similar to other scheduler commands, such as ccqsub, ccqstat and ccqdel with options that map across all the schedulers. Most of the configuration for items such as auto-scaling, instance type, spot instance price, etc. are heuristically determined or configured through the job scripts themselves. Once the jobs have completed, and the billing time approaches, the instances are terminated.

CCQ Meta-Scheduler
SECURITY:
CloudyCluster was designed to follow AWS Security Best Practices including VPCs, bastion hosts, network access restrictions, and it follows the least privilege philosophy and only opens access as needed, including dynamic access based on software enablement and disablement. Clusters are all launched in users own accounts, allowing them to meet any compliance requirements around their direct business processes. Clusters are also tied to the region the control instance is launched into, so resources can remain in a required jurisdiction.
CUSTOMIZATION AND SOFTWARE:
CloudyCluster comes with a wide variety of standard HPC libraries and applications, but with any HPC environment custom software will need to be added. CloudyCluster provides two methods to accomplish this. Software can be installed in a shared EFS mount that is preconfigured to enable modules. The AWS Marketplace AMI can also be launched with a special cloud formation template that does not start any services, and software can be added to an instance, you can create a new franken-AMI based on the running instance, then launch the new AMI as a control instance. All of the clusters created from that new installation will have the new software additions.
COST:
CloudyCluster allows users to limit their costs by providing job-based auto-scaling through CCQ. If constant computation is not needed users can pause instances or the entire cluster. Easy cluster resumption keeps costs down but retains ready access when computational resources are needed. If users have flexibility in their computation schedule needs, they can cut costs further with AWS spot instances. With support for AWS spot instances, jobs wait until the AWS spot market price matches (or is less than) the bid price in the CCQ job. The compute group spins up when availability arises and the job is processed.
PERFORMANCE:
CloudyCluster automatically creates placement groups for compute groups and enables enhanced networking for instance types that support it, providing optimal network performance and low ethernet latency in the cloud.
CONCLUSION:
CloudyCluster has tried to optimise Cloud HPC for time, reducing the time invested before computation can happen for large parallel workloads. The cloud has enabled this capability by providing rich APIs that platforms can interact with, bringing about automated computational environment build up, auto-scaling and tear down. As the CloudLightning project is enabling collaborative research into how to best optimise cloud environments for the future, we hope existing products such as CloudyCluster can provide insight and iterative improvement in the industry.
Thank you for your time. If you are interested in learning more about CloudyCluster please visitCloudyCluster.com or drop me a note at boydw at omnibond.com
This is a “reprint” of the CloudLightning Project Post